
- The objective of this study is to apply the Deep Reinforcement (DRL) algorithm to USA stocks yielding +4% DIV in 2022-23 (according to @buyingincome):
- Today we focus on Altria Group, Inc. (NYSE: MO) – a Dividend King moving beyond smoking. This post is a continuation of our previous case study dedicated to the candlestick-based Donchian channel trading indicator to identify potential breakouts and retracements of the $MO stock. Recall that our results appeared to be consistent with the TradingView and @simply_robo technical analysis summary and recommendations.
- Problem: Accurate predictions of stock prices is the common concerns of stock traders. This is because the majority of stock prices are highly volatile. The correlation between various factors is frequently so obscure that it is rather difficult to isolate the factors affecting rapid fluctuations of stock prices.
- Solution: Recent advances in DRL have enabled more accurate stock forecasting, and the majority of papers have demonstrated that their models can outperform the market average returns.
- Testimonies:
MLQ.ai: In fact, many AI experts agree that DRL is likely to be the best path towards AGI, or artificial general intelligence.
Spinning Up in DRL at OpenAI: “We believe that deep learning generally—and DRL specifically—will play central roles in the development of powerful AI technology.”
- This project intends to leverage DRL in stock portfolio management.
Key assumptions and limitations of the DRL framework:
- trading has no impact on the market
- only single stock type is supported
- only 3 basic actions: buy, hold, sell (no short selling or other complex actions)
- the agent performs only 1 action for portfolio reallocation at the end of each trade day
- all reallocations can be finished at the closing prices
- no missing data in price history
- no transaction cost.
Key challenges of the DRL framework:
- implementing algorithms from scratch with a thorough understanding of their pros and cons
- building a reliable reward mechanism (learning tends to be stationary/stuck in local optima quite often)
- ensuring the framework is scalable and extensible.
Flow Chart
The flowchart below illustrates the DRL procedure for agent-environment interaction at a high level. The goal is to maximize the agent’s reward in a limited number of actions by mapping environmental states to actions. The reward function serves as the overarching goal of training and serves as the standard against which all other factors are measured.

Key Steps
The key steps for designing a DRL model are as follows:
- Importing Libraries
- Create the agent who will make all decisions
- Define basic functions for formatting the values, sigmoid function, reading the data file, etc
- Training the agent
- Evaluating the agent performance.
Algorithm
let’s set the working directory
import os
os.chdir(‘YOURPATH’)
os. getcwd()
and download the stock data
import yfinance as yf
data = yf.download(“MO”, start=”2022-01-03″, end=”2023-03-22″)
[*********************100%***********************] 1 of 1 completed
We need to install the extra library
!pip install chainer
and import other libraries
import time
import copy
import numpy as np
import pandas as pd
import chainer
import chainer.functions as F
import chainer.links as L
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
init_notebook_mode()
Let’s check the data structure
data.tail()
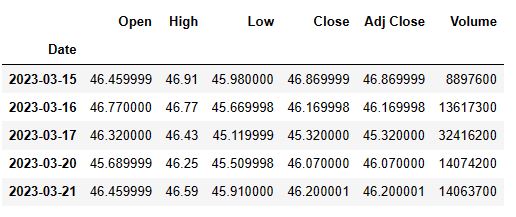
data.shape
(305, 6)
data.info()
<class 'pandas.core.frame.DataFrame'> DatetimeIndex: 305 entries, 2022-01-03 to 2023-03-21 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Open 305 non-null float64 1 High 305 non-null float64 2 Low 305 non-null float64 3 Close 305 non-null float64 4 Adj Close 305 non-null float64 5 Volume 305 non-null int64 dtypes: float64(5), int64(1) memory usage: 24.8 KB
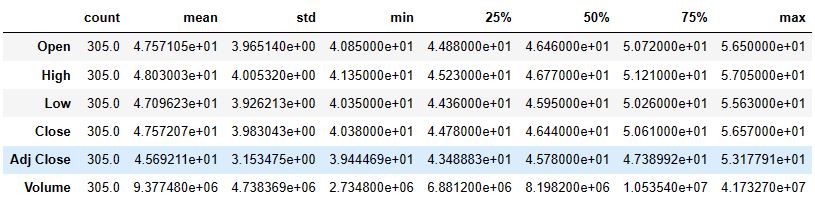
data.describe().T
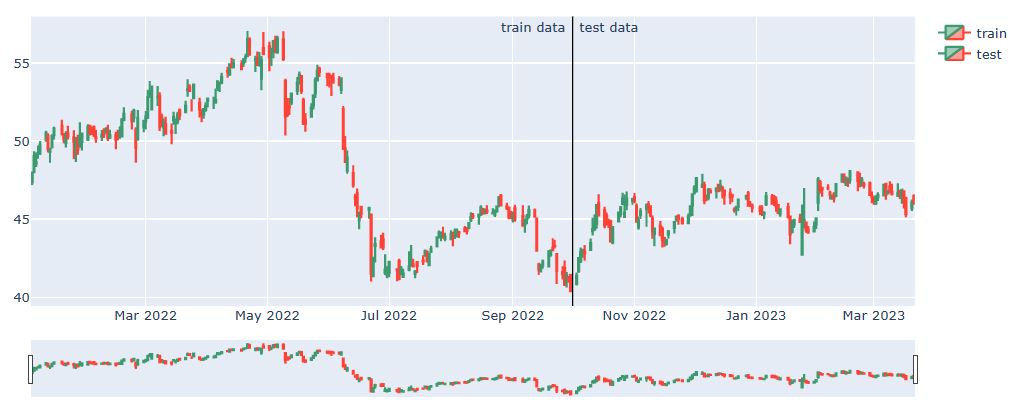
Train/test data split:
date_split = ‘2022-10-01’
train = data[:date_split]
test = data[date_split:]
len(train), len(test)
(188, 117)
let’s plot these two datasets using plotly
def plot_train_test(train, test, date_split):
data = [
Candlestick(x=train.index, open=train['Open'], high=train['High'], low=train['Low'], close=train['Close'], name='train'),
Candlestick(x=test.index, open=test['Open'], high=test['High'], low=test['Low'], close=test['Close'], name='test')
]
layout = {
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)
plot_train_test(train, test, date_split)
Let’s define the class Environment1
class Environment1:
def __init__(self, data, history_t=90):
self.data = data
self.history_t = history_t
self.reset()
def reset(self):
self.t = 0
self.done = False
self.profits = 0
self.positions = []
self.position_value = 0
self.history = [0 for _ in range(self.history_t)]
return [self.position_value] + self.history # obs
def step(self, act):
reward = 0
# act = 0: stay, 1: buy, 2: sell
if act == 1:
self.positions.append(self.data.iloc[self.t, :]['Close'])
elif act == 2: # sell
if len(self.positions) == 0:
reward = -1
else:
profits = 0
for p in self.positions:
profits += (self.data.iloc[self.t, :]['Close'] - p)
reward += profits
self.profits += profits
self.positions = []
# set next time
self.t += 1
self.position_value = 0
for p in self.positions:
self.position_value += (self.data.iloc[self.t, :]['Close'] - p)
self.history.pop(0)
self.history.append(self.data.iloc[self.t, :]['Close'] - self.data.iloc[(self.t-1), :]['Close'])
# clipping reward
if reward > 0:
reward = 1
elif reward < 0:
reward = -1
return [self.position_value] + self.history, reward, self.done # obs, reward, done
Let’s invoke this class as follows:
env = Environment1(train)
print(env.reset())
for _ in range(3):
pact = np.random.randint(3)
print(env.step(pact))
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] ([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.05999755859375], 0, False) ([-0.3899993896484375, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.05999755859375, -0.3899993896484375], 0, False) ([0.18000030517578125, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1.05999755859375, -0.3899993896484375, 0.5699996948242188], 0, False)
Let’s define DQN
def train_dqn(env):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
)
def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
epoch_num = 50
step_max = len(env.data)-1
memory_size = 200
batch_size = 20
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5
memory = []
total_step = 0
total_rewards = []
total_losses = []
start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max:
# select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
# act
obs, reward, done = env.step(pact)
# add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0)
# train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=bool)
q = Q(b_pobs)
maxq = np.max(Q_ast(b_obs).data, axis=1)
target = copy.deepcopy(q.data)
for j in range(batch_size):
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q)
# epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease
# next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards
Let’s invoke this class
Q, total_losses, total_rewards = train_dqn(Environment1(train))
5 0.26599999999999935 935 -15.6 8.378280513733625 1.882044792175293 10 0.0999999999999992 1870 1.6 212.92116943709553 2.9393341541290283 15 0.0999999999999992 2805 0.0 197.6353921659291 3.1940603256225586 20 0.0999999999999992 3740 -0.2 76.21642142683268 2.6600332260131836 25 0.0999999999999992 4675 8.4 16.361252902820706 2.7394282817840576 30 0.0999999999999992 5610 10.6 11.873821935988962 2.6485908031463623 35 0.0999999999999992 6545 10.2 18.863544968515633 2.7909960746765137 40 0.0999999999999992 7480 10.8 11.163612035475671 2.586214065551758 45 0.0999999999999992 8415 9.0 5.021430662972852 2.617769956588745 50 0.0999999999999992 9350 13.6 6.592287559248507 2.6137917041778564
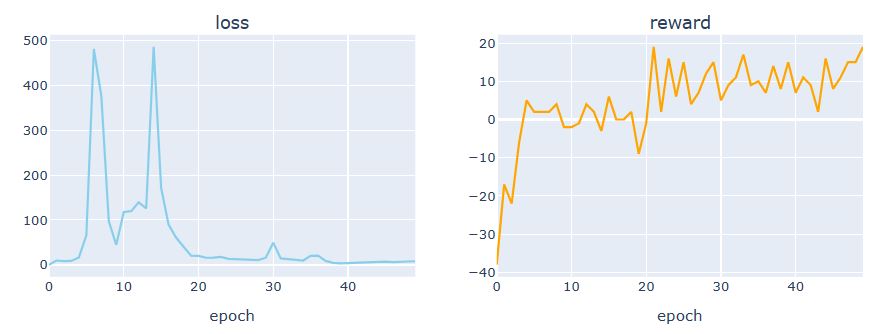
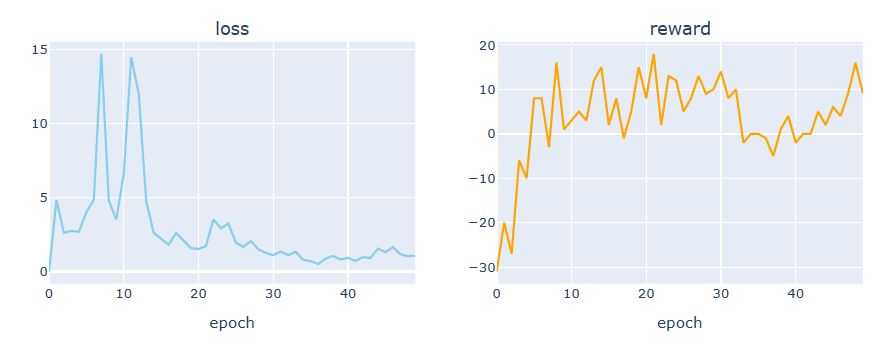
Let’s plot the loss vs reward using plotly
def plot_loss_reward(total_losses, total_rewards):
figure = tools.make_subplots(rows=1, cols=2, subplot_titles=('loss', 'reward'), print_grid=False)
figure.append_trace(Scatter(y=total_losses, mode='lines', line=dict(color='skyblue')), 1, 1)
figure.append_trace(Scatter(y=total_rewards, mode='lines', line=dict(color='orange')), 1, 2)
figure['layout']['xaxis1'].update(title='epoch')
figure['layout']['xaxis2'].update(title='epoch')
figure['layout'].update(height=400, width=900, showlegend=False)
iplot(figure)
plot_loss_reward(total_losses, total_rewards)
Let’s compare the DQN train/test s-reward vs profits
def plot_train_test_by_q(train_env, test_env, Q, algorithm_name):
# train
pobs = train_env.reset()
train_acts = []
train_rewards = []
for _ in range(len(train_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
train_acts.append(pact)
obs, reward, done = train_env.step(pact)
train_rewards.append(reward)
pobs = obs
train_profits = train_env.profits
# test
pobs = test_env.reset()
test_acts = []
test_rewards = []
for _ in range(len(test_env.data)-1):
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
test_acts.append(pact)
obs, reward, done = test_env.step(pact)
test_rewards.append(reward)
pobs = obs
test_profits = test_env.profits
# plot
train_copy = train_env.data.copy()
test_copy = test_env.data.copy()
train_copy['act'] = train_acts + [np.nan]
train_copy['reward'] = train_rewards + [np.nan]
test_copy['act'] = test_acts + [np.nan]
test_copy['reward'] = test_rewards + [np.nan]
train0 = train_copy[train_copy['act'] == 0]
train1 = train_copy[train_copy['act'] == 1]
train2 = train_copy[train_copy['act'] == 2]
test0 = test_copy[test_copy['act'] == 0]
test1 = test_copy[test_copy['act'] == 1]
test2 = test_copy[test_copy['act'] == 2]
act_color0, act_color1, act_color2 = 'gray', 'cyan', 'magenta'
data = [
Candlestick(x=train0.index, open=train0['Open'], high=train0['High'], low=train0['Low'], close=train0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=train1.index, open=train1['Open'], high=train1['High'], low=train1['Low'], close=train1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=train2.index, open=train2['Open'], high=train2['High'], low=train2['Low'], close=train2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2))),
Candlestick(x=test0.index, open=test0['Open'], high=test0['High'], low=test0['Low'], close=test0['Close'], increasing=dict(line=dict(color=act_color0)), decreasing=dict(line=dict(color=act_color0))),
Candlestick(x=test1.index, open=test1['Open'], high=test1['High'], low=test1['Low'], close=test1['Close'], increasing=dict(line=dict(color=act_color1)), decreasing=dict(line=dict(color=act_color1))),
Candlestick(x=test2.index, open=test2['Open'], high=test2['High'], low=test2['Low'], close=test2['Close'], increasing=dict(line=dict(color=act_color2)), decreasing=dict(line=dict(color=act_color2)))
]
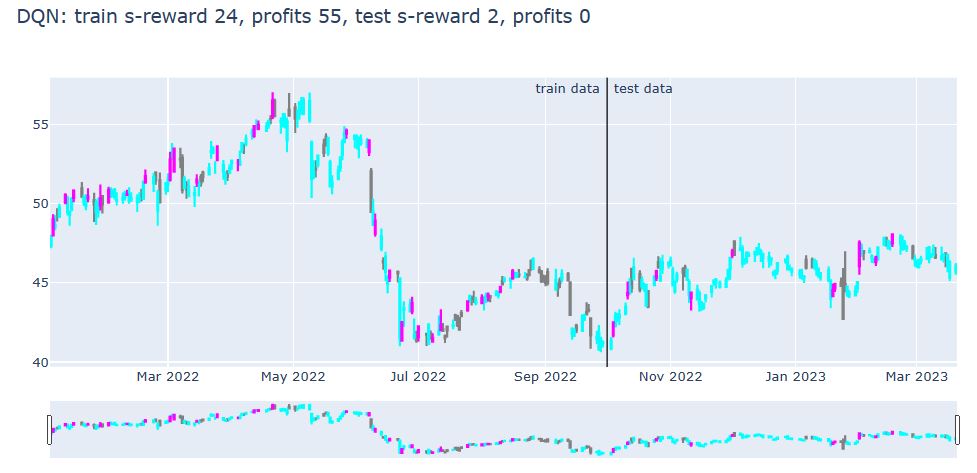
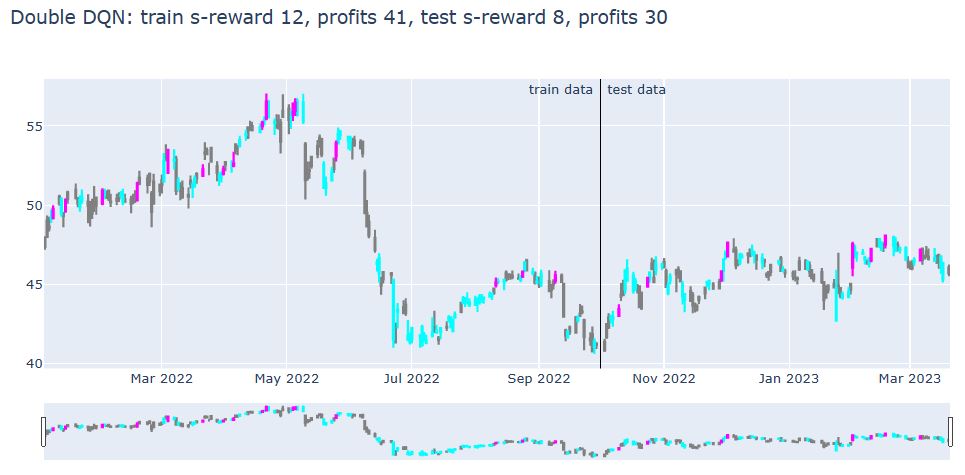
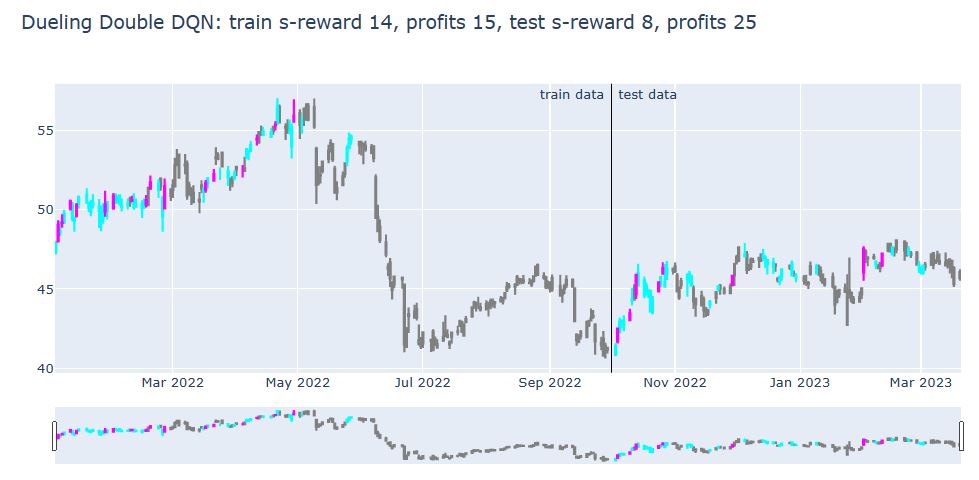
title = '{}: train s-reward {}, profits {}, test s-reward {}, profits {}'.format(
algorithm_name,
int(sum(train_rewards)),
int(train_profits),
int(sum(test_rewards)),
int(test_profits)
)
layout = {
'title': title,
'showlegend': False,
'shapes': [
{'x0': date_split, 'x1': date_split, 'y0': 0, 'y1': 1, 'xref': 'x', 'yref': 'paper', 'line': {'color': 'rgb(0,0,0)', 'width': 1}}
],
'annotations': [
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'left', 'text': ' test data'},
{'x': date_split, 'y': 1.0, 'xref': 'x', 'yref': 'paper', 'showarrow': False, 'xanchor': 'right', 'text': 'train data '}
]
}
figure = Figure(data=data, layout=layout)
iplot(figure)
plot_train_test_by_q(Environment1(train), Environment1(test), Q, ‘DQN’)
Let’s look at Double DQN
def train_ddqn(env):
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
)
def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
epoch_num = 50
step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5
memory = []
total_step = 0
total_rewards = []
total_losses = []
start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max:
# select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
# act
obs, reward, done = env.step(pact)
# add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0)
# train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q)
# epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease
# next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards
Let’s call this function
Q, total_losses, total_rewards = train_ddqn(Environment1(train))
5 0.26599999999999935 935 -18.8 2.58153205383569 1.4034900665283203 10 0.0999999999999992 1870 6.0 6.38107671495527 2.023881196975708 15 0.0999999999999992 2805 7.6 8.102847685292364 1.800950527191162 20 0.0999999999999992 3740 5.8 2.074553413130343 1.7402253150939941 25 0.0999999999999992 4675 10.6 2.588063887692988 1.7767736911773682 30 0.0999999999999992 5610 9.0 1.692694649938494 1.7709689140319824 35 0.0999999999999992 6545 6.0 1.140931996051222 1.732893943786621 40 0.0999999999999992 7480 -0.2 0.7938342220382765 1.6818647384643555 45 0.0999999999999992 8415 1.0 1.0210695683024824 1.8096415996551514 50 0.0999999999999992 9350 8.8 1.2512135957367718 1.974039077758789
let’s plot loss vs reward
plot_loss_reward(total_losses, total_rewards)
let’s plot Double DQN train/test s-reward vs profits
plot_train_test_by_q(Environment1(train), Environment1(test), Q, ‘Double DQN’)
Let’s look at Dueling Double DQN
def train_dddqn(env):
""" <<< Double DQN -> Dueling Double DQN
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, output_size)
)
def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
y = self.fc3(h)
return y
def reset(self):
self.zerograds()
=== """
class Q_Network(chainer.Chain):
def __init__(self, input_size, hidden_size, output_size):
super(Q_Network, self).__init__(
fc1 = L.Linear(input_size, hidden_size),
fc2 = L.Linear(hidden_size, hidden_size),
fc3 = L.Linear(hidden_size, hidden_size//2),
fc4 = L.Linear(hidden_size, hidden_size//2),
state_value = L.Linear(hidden_size//2, 1),
advantage_value = L.Linear(hidden_size//2, output_size)
)
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
def __call__(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
hs = F.relu(self.fc3(h))
ha = F.relu(self.fc4(h))
state_value = self.state_value(hs)
advantage_value = self.advantage_value(ha)
advantage_mean = (F.sum(advantage_value, axis=1)/float(self.output_size)).reshape(-1, 1)
q_value = F.concat([state_value for _ in range(self.output_size)], axis=1) + (advantage_value - F.concat([advantage_mean for _ in range(self.output_size)], axis=1))
return q_value
def reset(self):
self.zerograds()
""" >>> """
Q = Q_Network(input_size=env.history_t+1, hidden_size=100, output_size=3)
Q_ast = copy.deepcopy(Q)
optimizer = chainer.optimizers.Adam()
optimizer.setup(Q)
epoch_num = 50
step_max = len(env.data)-1
memory_size = 200
batch_size = 50
epsilon = 1.0
epsilon_decrease = 1e-3
epsilon_min = 0.1
start_reduce_epsilon = 200
train_freq = 10
update_q_freq = 20
gamma = 0.97
show_log_freq = 5
memory = []
total_step = 0
total_rewards = []
total_losses = []
start = time.time()
for epoch in range(epoch_num):
pobs = env.reset()
step = 0
done = False
total_reward = 0
total_loss = 0
while not done and step < step_max:
# select act
pact = np.random.randint(3)
if np.random.rand() > epsilon:
pact = Q(np.array(pobs, dtype=np.float32).reshape(1, -1))
pact = np.argmax(pact.data)
# act
obs, reward, done = env.step(pact)
# add memory
memory.append((pobs, pact, reward, obs, done))
if len(memory) > memory_size:
memory.pop(0)
# train or update q
if len(memory) == memory_size:
if total_step % train_freq == 0:
shuffled_memory = np.random.permutation(memory)
memory_idx = range(len(shuffled_memory))
for i in memory_idx[::batch_size]:
batch = np.array(shuffled_memory[i:i+batch_size])
b_pobs = np.array(batch[:, 0].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_pact = np.array(batch[:, 1].tolist(), dtype=np.int32)
b_reward = np.array(batch[:, 2].tolist(), dtype=np.int32)
b_obs = np.array(batch[:, 3].tolist(), dtype=np.float32).reshape(batch_size, -1)
b_done = np.array(batch[:, 4].tolist(), dtype=np.bool)
q = Q(b_pobs)
""" <<< DQN -> Double DQN
maxq = np.max(Q_ast(b_obs).data, axis=1)
=== """
indices = np.argmax(q.data, axis=1)
maxqs = Q_ast(b_obs).data
""" >>> """
target = copy.deepcopy(q.data)
for j in range(batch_size):
""" <<< DQN -> Double DQN
target[j, b_pact[j]] = b_reward[j]+gamma*maxq[j]*(not b_done[j])
=== """
target[j, b_pact[j]] = b_reward[j]+gamma*maxqs[j, indices[j]]*(not b_done[j])
""" >>> """
Q.reset()
loss = F.mean_squared_error(q, target)
total_loss += loss.data
loss.backward()
optimizer.update()
if total_step % update_q_freq == 0:
Q_ast = copy.deepcopy(Q)
# epsilon
if epsilon > epsilon_min and total_step > start_reduce_epsilon:
epsilon -= epsilon_decrease
# next step
total_reward += reward
pobs = obs
step += 1
total_step += 1
total_rewards.append(total_reward)
total_losses.append(total_loss)
if (epoch+1) % show_log_freq == 0:
log_reward = sum(total_rewards[((epoch+1)-show_log_freq):])/show_log_freq
log_loss = sum(total_losses[((epoch+1)-show_log_freq):])/show_log_freq
elapsed_time = time.time()-start
print('\t'.join(map(str, [epoch+1, epsilon, total_step, log_reward, log_loss, elapsed_time])))
start = time.time()
return Q, total_losses, total_rewards
Let’s call the function
plot_train_test_by_q(Environment1(train), Environment1(test), Q, ‘Dueling Double DQN’)
Summary
- This work represents a DRL model to generate profitable trades in the $MO stock data, effectively overcoming the limitations of supervised ML approaches.
- Results show that the accuracy of DRL in stock price prediction as well as the stability of rapid prediction have both been significantly enhanced.
- Therefore, it is more suitable for use in periods of turbulent market compared to traditional forecast methods.
- Overall, this study demonstrates the superiority of DRL in financial markets over other types of ML/AI and proves its credibility and advantages of investment decision-making.
Explore More
The Donchian Channel vs Buy-and-Hold Breakout Trading Systems – $MO Use-Case


Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.

Leave a comment