
Pilots Related to HealthTech

Infographic
These plots illustrate the most basic application of ML/AI in BCD as the binary classification problem. Classification usually refers to any kind of problem where a specific type of class label is the result to be predicted from the given input field of data. This is a task which assigns a label value (“benign” or “malignant”) to a specific class and then can identify a particular type to be of one kind or another. Generally, one is considered as the normal state and the other is considered to be the abnormal state. In BCD, ” No cancer detected” is a normal state and ” Cancer detected” represents the abnormal state. For any model, you will require a training dataset with many examples of inputs and outputs from which the model will train itself. The training data must include all the possible scenarios of the problem and must have sufficient data for each label for the model to be trained correctly. Class labels are often returned as string values and hence needs to be encoded into an integer like either representing 0 for “benign” or 1 for “malignant”. For each training example, one can also create a model which predicts the Bernoulli probability for the output. In short, it returns a discrete value [0-1] that covers all cases and will give the output as either the outcome will have a value of 1 or 0.





We have tried several types of classification ML algorithms (ALG):
1 Logistic Regression 95.8%
2 SVM 97.2%
3 Naive Bayes 91.6% (worst)
4 Random Forest 98.6% (best)
ALG 1 & 2 yield similar accuracy,
All ALG yield acceptable >90% accuracy.
We can make the confusion matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(test,predict)
sns.heatmap(cm,annot=True)
We can view it as the 2×2 table
| 88(87) | 1(3) |
| 2(3) | 52(50) |
Then we can compute the key metrics:
P=0.98 (0.96)
R=0.88 (0.96)
Hence,
F1 = 0.92 (0.96) = 0.94 +/- 0.02.
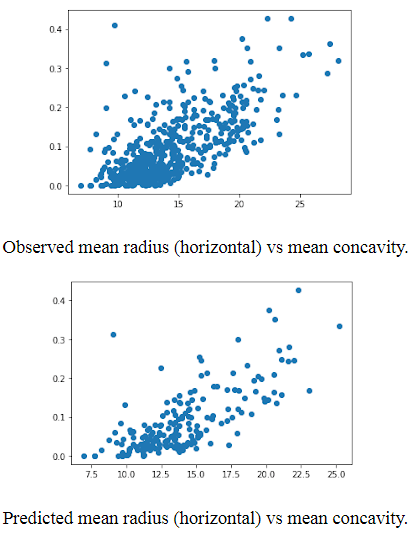
We can see that our model is working very efficiently and accurately in classifying whether the BC is of malignant type or benign type. In addition to scikit-learn, we have visualized the data using pandas and matplotlib libraries.
Cloud ML-as-a-Service
Technology
AWS now provides a robust, cloud-based service — Amazon SageMaker — so that developers of all skill levels can use ML technology. SageMaker API enables developers to create, train, and deploy ML models into a production-ready hosted environment.
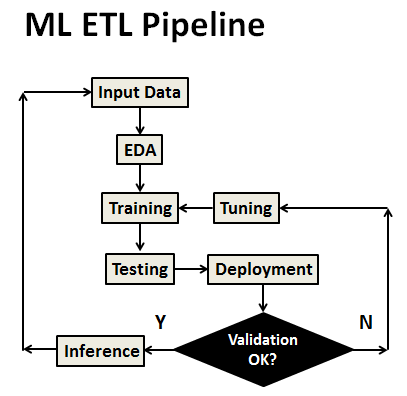
The GCP AutoML Tables is another available supervised ML service. It requires example data to train your model by implementing the standard ML ETL pipeline in Figure 4:
1. Gather your data: Determine the data you need for training and testing your model based on the outcome you want to achieve
2. Prepare your data: Make sure your data is properly formatted before and after data import
3. Train: Set parameters and build your model
4. Evaluate: Review model metrics
5. Test: Try your model on test data
6. Deploy and predict: Make your model available to use.
Here, models can have both numerical and categorical features.
Finally, MS Azure ML Studio breaks down ML into five algorithm groups:
- Two-Class (or Binary) Classification
- Multi- Class Classification
- Clustering
- Anomaly Detection
- Regression
In the BCD study the focus is on the Azure ML Two-Class (or Binary) and Multi-Class Classification algorithms.



Leave a comment