- In this post, we will walk through the Detectron2 object detection, image recognition and segmentation platform that has become one of Facebook AI Research (FAIR)’s most widely adopted open source projects. It supports a number of computer vision (CV) research projects and production applications in Metaverse.
- In fact, we are using the second generation of Detectron, with important enhancements for use in amenity detection and beyond.
- It is remarkable that the platform includes new capabilities such as panoptic segmentation, Densepose, Cascade R-CNN, rotated bounding boxes, PointRend, DeepLab, ViTDet, MViTv2 etc.
- Our goal is to test and validate a large set of baseline workflows and trained models available for download in the Detectron2 Model Zoo.
Method
- Object detection is a common CV technique that locates and identifies specific types of objects in an image. Those types of objects can be anything from humans, animals, or vehicles to very specific items such as brands of chips or types of building materials.
- Successfully detecting a human/object in a video/image requires building an API that involves both object recognition and image classification. Deep learning models are fed large amounts of images to train them what a particular object looks like. The trained models can then learn to identify those objects in new scenarios.
Computer Resources
Python 3 Google Compute Engine backend (GPU)
Install Detectron2
!python -m pip install pyyaml==5.1
import sys, os, distutils.core
# Note: This is a faster way to install detectron2 in Colab, but it does not include all functionalities.
# See https://detectron2.readthedocs.io/tutorials/install.html for full installation instructions
!git clone ‘https://github.com/facebookresearch/detectron2’
dist = distutils.core.run_setup(“./detectron2/setup.py”)
!python -m pip install {‘ ‘.join([f”‘{x}’” for x in dist.install_requires])}
sys.path.insert(0, os.path.abspath(‘./detectron2’))
# Properly install detectron2. (Please do not install twice in both ways)
# !python -m pip install ‘git+https://github.com/facebookresearch/detectron2.git’
Import Libraries
import torch, detectron2
!nvcc –version
TORCH_VERSION = “.”.join(torch.__version__.split(“.”)[:2])
CUDA_VERSION = torch.__version__.split(“+”)[-1]
print(“torch: “, TORCH_VERSION, “; cuda: “, CUDA_VERSION)
print(“detectron2:”, detectron2.__version__)
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Tue_Mar__8_18:18:20_PST_2022 Cuda compilation tools, release 11.6, V11.6.124 Build cuda_11.6.r11.6/compiler.31057947_0 torch: 1.13 ; cuda: cu116 detectron2: 0.6
# Some basic setup:
# Setup detectron2 logger
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
from google.colab.patches import cv2_imshow
# import some common detectron2 utilities
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
Run a pre-trained detectron2 model
We first download an image from the COCO dataset:
!wget http://images.cocodataset.org/val2017/000000439715.jpg -q -O input.jpg
im = cv2.imread(“./input.jpg”)
cv2_imshow(im)

Then, we create a detectron2 config and a detectron2 DefaultPredictor to run inference on this image.
cfg = get_cfg()
# add project-specific config (e.g., TensorMask) here if you’re not running a model in detectron2’s core library
cfg.merge_from_file(model_zoo.get_config_file(“COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml”))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set threshold for this model
# Find a model from detectron2’s model zoo. You can use the https://dl.fbaipublicfiles… url as well
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(“COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml”)
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
# look at the outputs. See https://detectron2.readthedocs.io/tutorials/models.html#model-output-format for specification
print(outputs[“instances”].pred_classes)
print(outputs[“instances”].pred_boxes)
tensor([17, 0, 0, 0, 0, 0, 0, 0, 25, 0, 25, 25, 0, 0, 24], device=’cuda:0′) Boxes(tensor([[126.6035, 244.8977, 459.8291, 480.0000], [251.1083, 157.8127, 338.9731, 413.6379], [114.8496, 268.6864, 148.2352, 398.8111], [ 0.8217, 281.0327, 78.6072, 478.4210], [ 49.3953, 274.1229, 80.1545, 342.9808], [561.2248, 271.5816, 596.2755, 385.2552], [385.9072, 270.3125, 413.7130, 304.0397], [515.9295, 278.3744, 562.2792, 389.3802], [335.2409, 251.9167, 414.7491, 275.9375], [350.9300, 269.2060, 386.0984, 297.9081], [331.6292, 230.9996, 393.2759, 257.2009], [510.7349, 263.2656, 570.9865, 295.9194], [409.0841, 271.8646, 460.5582, 356.8722], [506.8767, 283.3257, 529.9403, 324.0392], [594.5663, 283.4820, 609.0577, 311.4124]], device=’cuda:0′))
# We can use `Visualizer` to draw the predictions on the image.
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs[“instances”].to(“cpu”))
cv2_imshow(out.get_image()[:, :, ::-1])

Train on a custom dataset
In this section, we show how to train an existing detectron2 model on a custom dataset in a new format.
We use the balloon segmentation dataset which only has one class: balloon. We’ll train a balloon segmentation model from an existing model pre-trained on COCO dataset, available in detectron2’s model zoo.
Note that COCO dataset does not have the “balloon” category. We’ll be able to recognize this new class in a few minutes.
Prepare the dataset
# download, decompress the data
!wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip balloon_dataset.zip > /dev/null
–2023-02-19 12:09:06– https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip Resolving github.com (github.com)… 20.205.243.166 Connecting to github.com (github.com)|20.205.243.166|:443… connected. HTTP request sent, awaiting response… 302 Found Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/107595270/737339e2-2b83-11e8-856a-188034eb3468?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20230219%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230219T120906Z&X-Amz-Expires=300&X-Amz-Signature=b8177de12087f5fd6149af389d672146a0a621579f31638cf41b4547d8a5eaf9&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=107595270&response-content-disposition=attachment%3B%20filename%3Dballoon_dataset.zip&response-content-type=application%2Foctet-stream [following] –2023-02-19 12:09:06– https://objects.githubusercontent.com/github-production-release-asset-2e65be/107595270/737339e2-2b83-11e8-856a-188034eb3468?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20230219%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20230219T120906Z&X-Amz-Expires=300&X-Amz-Signature=b8177de12087f5fd6149af389d672146a0a621579f31638cf41b4547d8a5eaf9&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=107595270&response-content-disposition=attachment%3B%20filename%3Dballoon_dataset.zip&response-content-type=application%2Foctet-stream Resolving objects.githubusercontent.com (objects.githubusercontent.com)… 185.199.108.133, 185.199.109.133, 185.199.110.133, … Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.108.133|:443… connected. HTTP request sent, awaiting response… 200 OK Length: 38741381 (37M) [application/octet-stream] Saving to: ‘balloon_dataset.zip’ balloon_dataset.zip 100%[===================>] 36.95M 2.79MB/s in 20s 2023-02-19 12:09:26 (1.89 MB/s) – ‘balloon_dataset.zip’ saved [38741381/38741381]
Register the balloon dataset to detectron2, following the detectron2 custom dataset tutorial. Here, the dataset is in its custom format, therefore we write a function to parse it and prepare it into detectron2’s standard format. User should write such a function when using a dataset in custom format. See the tutorial for more details.
# if your dataset is in COCO format, this cell can be replaced by the following three lines:
# from detectron2.data.datasets import register_coco_instances
# register_coco_instances(“my_dataset_train”, {}, “json_annotation_train.json”, “path/to/image/dir”)
# register_coco_instances(“my_dataset_val”, {}, “json_annotation_val.json”, “path/to/image/dir”)
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, “via_region_data.json”)
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v[“filename”])
height, width = cv2.imread(filename).shape[:2]
record[“file_name”] = filename
record[“image_id”] = idx
record[“height”] = height
record[“width”] = width
annos = v[“regions”]
objs = []
for _, anno in annos.items():
assert not anno[“region_attributes”]
anno = anno[“shape_attributes”]
px = anno[“all_points_x”]
py = anno[“all_points_y”]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
“bbox”: [np.min(px), np.min(py), np.max(px), np.max(py)],
“bbox_mode”: BoxMode.XYXY_ABS,
“segmentation”: [poly],
“category_id”: 0,
}
objs.append(obj)
record[“annotations”] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in [“train”, “val”]:
DatasetCatalog.register(“balloon_” + d, lambda d=d: get_balloon_dicts(“balloon/” + d))
MetadataCatalog.get(“balloon_” + d).set(thing_classes=[“balloon”])
balloon_metadata = MetadataCatalog.get(“balloon_train”)
To verify the dataset is in correct format, let’s visualize the annotations of randomly selected samples in the training set:
dataset_dicts = get_balloon_dicts(“balloon/train”)
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d[“file_name”])
visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
out = visualizer.draw_dataset_dict(d)
cv2_imshow(out.get_image()[:, :, ::-1])


Train!
Now, let’s fine-tune a COCO-pretrained R50-FPN Mask R-CNN model on the balloon dataset. It takes ~2 minutes to train 300 iterations on a P100 GPU.
from detectron2.engine import DefaultTrainer
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(“COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml”))
cfg.DATASETS.TRAIN = (“balloon_train”,)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(“COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml”) # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2 # This is the real “batch size” commonly known to deep learning people
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # The “RoIHead batch size”. 128 is faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
Output:
[02/19 12:10:49 d2.engine.defaults]: Model:
GeneralizedRCNN(
(backbone): FPN(
(fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelMaxPool()
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): StandardROIHeads(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(box_head): FastRCNNConvFCHead(
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=12544, out_features=1024, bias=True)
(fc_relu1): ReLU()
(fc2): Linear(in_features=1024, out_features=1024, bias=True)
(fc_relu2): ReLU()
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=4, bias=True)
)
(mask_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(14, 14), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(14, 14), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(mask_head): MaskRCNNConvUpsampleHead(
(mask_fcn1): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn3): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn4): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(deconv): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2))
(deconv_relu): ReLU()
(predictor): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
[02/19 12:10:51 d2.data.build]: Removed 0 images with no usable annotations. 61 images left.
[02/19 12:10:51 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 255 |
| | |
[02/19 12:10:51 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[02/19 12:10:51 d2.data.build]: Using training sampler TrainingSampler
[02/19 12:10:51 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'>
[02/19 12:10:51 d2.data.common]: Serializing 61 elements to byte tensors and concatenating them all ...
[02/19 12:10:51 d2.data.common]: Serialized dataset takes 0.17 MiB
[02/19 12:10:53 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.cls_score.weight' to the model due to incompatible shapes: (81, 1024) in the checkpoint but (2, 1024) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.cls_score.bias' to the model due to incompatible shapes: (81,) in the checkpoint but (2,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.bbox_pred.weight' to the model due to incompatible shapes: (320, 1024) in the checkpoint but (4, 1024) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.bbox_pred.bias' to the model due to incompatible shapes: (320,) in the checkpoint but (4,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.mask_head.predictor.weight' to the model due to incompatible shapes: (80, 256, 1, 1) in the checkpoint but (1, 256, 1, 1) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.mask_head.predictor.bias' to the model due to incompatible shapes: (80,) in the checkpoint but (1,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Some model parameters or buffers are not found in the checkpoint:
roi_heads.box_predictor.bbox_pred.{bias, weight}
roi_heads.box_predictor.cls_score.{bias, weight}
roi_heads.mask_head.predictor.{bias, weight}
[02/19 12:10:55 d2.engine.train_loop]: Starting training from iteration 0 [02/19 12:11:07 d2.utils.events]: eta: 0:01:59 iter: 19 total_loss: 2.023 loss_cls: 0.6556 loss_box_reg: 0.6125 loss_mask: 0.6841 loss_rpn_cls: 0.02502 loss_rpn_loc: 0.006673 time: 0.4301 last_time: 0.3398 data_time: 0.0500 last_data_time: 0.0149 lr: 1.6068e-05 max_mem: 2722M [02/19 12:11:16 d2.utils.events]: eta: 0:01:56 iter: 39 total_loss: 1.932 loss_cls: 0.5705 loss_box_reg: 0.5005 loss_mask: 0.6047 loss_rpn_cls: 0.04536 loss_rpn_loc: 0.009314 time: 0.4473 last_time: 0.4450 data_time: 0.0118 last_data_time: 0.0104 lr: 3.2718e-05 max_mem: 2722M [02/19 12:11:25 d2.utils.events]: eta: 0:01:47 iter: 59 total_loss: 1.64 loss_cls: 0.4327 loss_box_reg: 0.6647 loss_mask: 0.4895 loss_rpn_cls: 0.02879 loss_rpn_loc: 0.007163 time: 0.4509 last_time: 0.4086 data_time: 0.0148 last_data_time: 0.0139 lr: 4.9367e-05 max_mem: 2844M [02/19 12:11:34 d2.utils.events]: eta: 0:01:38 iter: 79 total_loss: 1.4 loss_cls: 0.3623 loss_box_reg: 0.654 loss_mask: 0.3547 loss_rpn_cls: 0.01902 loss_rpn_loc: 0.004264 time: 0.4500 last_time: 0.4808 data_time: 0.0139 last_data_time: 0.0138 lr: 6.6017e-05 max_mem: 2844M [02/19 12:11:44 d2.utils.events]: eta: 0:01:30 iter: 99 total_loss: 1.233 loss_cls: 0.3126 loss_box_reg: 0.6105 loss_mask: 0.284 loss_rpn_cls: 0.01725 loss_rpn_loc: 0.007273 time: 0.4542 last_time: 0.4441 data_time: 0.0119 last_data_time: 0.0128 lr: 8.2668e-05 max_mem: 2844M [02/19 12:11:53 d2.utils.events]: eta: 0:01:21 iter: 119 total_loss: 1.161 loss_cls: 0.2431 loss_box_reg: 0.6564 loss_mask: 0.2261 loss_rpn_cls: 0.02933 loss_rpn_loc: 0.00754 time: 0.4584 last_time: 0.3965 data_time: 0.0158 last_data_time: 0.0099 lr: 9.9318e-05 max_mem: 2935M [02/19 12:12:03 d2.utils.events]: eta: 0:01:12 iter: 139 total_loss: 1.055 loss_cls: 0.2117 loss_box_reg: 0.6488 loss_mask: 0.1904 loss_rpn_cls: 0.01986 loss_rpn_loc: 0.007624 time: 0.4592 last_time: 0.5019 data_time: 0.0141 last_data_time: 0.0238 lr: 0.00011597 max_mem: 2935M [02/19 12:12:12 d2.utils.events]: eta: 0:01:04 iter: 159 total_loss: 0.8191 loss_cls: 0.1349 loss_box_reg: 0.4823 loss_mask: 0.1369 loss_rpn_cls: 0.01349 loss_rpn_loc: 0.005617 time: 0.4612 last_time: 0.5077 data_time: 0.0110 last_data_time: 0.0068 lr: 0.00013262 max_mem: 2935M [02/19 12:12:22 d2.utils.events]: eta: 0:00:55 iter: 179 total_loss: 0.7441 loss_cls: 0.1272 loss_box_reg: 0.4613 loss_mask: 0.1307 loss_rpn_cls: 0.01713 loss_rpn_loc: 0.01175 time: 0.4647 last_time: 0.4263 data_time: 0.0147 last_data_time: 0.0076 lr: 0.00014927 max_mem: 2935M [02/19 12:12:31 d2.utils.events]: eta: 0:00:45 iter: 199 total_loss: 0.4944 loss_cls: 0.0834 loss_box_reg: 0.2877 loss_mask: 0.09292 loss_rpn_cls: 0.01697 loss_rpn_loc: 0.005537 time: 0.4635 last_time: 0.4285 data_time: 0.0121 last_data_time: 0.0075 lr: 0.00016592 max_mem: 2935M [02/19 12:12:40 d2.utils.events]: eta: 0:00:36 iter: 219 total_loss: 0.4836 loss_cls: 0.09751 loss_box_reg: 0.2436 loss_mask: 0.0975 loss_rpn_cls: 0.01915 loss_rpn_loc: 0.008263 time: 0.4630 last_time: 0.4766 data_time: 0.0128 last_data_time: 0.0034 lr: 0.00018257 max_mem: 2935M [02/19 12:12:50 d2.utils.events]: eta: 0:00:27 iter: 239 total_loss: 0.3281 loss_cls: 0.05753 loss_box_reg: 0.1902 loss_mask: 0.07362 loss_rpn_cls: 0.007059 loss_rpn_loc: 0.004808 time: 0.4647 last_time: 0.5284 data_time: 0.0132 last_data_time: 0.0148 lr: 0.00019922 max_mem: 2935M [02/19 12:13:00 d2.utils.events]: eta: 0:00:18 iter: 259 total_loss: 0.3902 loss_cls: 0.07367 loss_box_reg: 0.217 loss_mask: 0.0701 loss_rpn_cls: 0.007356 loss_rpn_loc: 0.00689 time: 0.4665 last_time: 0.4862 data_time: 0.0125 last_data_time: 0.0010 lr: 0.00021587 max_mem: 2935M [02/19 12:13:10 d2.utils.events]: eta: 0:00:09 iter: 279 total_loss: 0.4429 loss_cls: 0.08022 loss_box_reg: 0.2024 loss_mask: 0.08986 loss_rpn_cls: 0.01052 loss_rpn_loc: 0.005888 time: 0.4681 last_time: 0.4567 data_time: 0.0127 last_data_time: 0.0059 lr: 0.00023252 max_mem: 2935M [02/19 12:13:20 d2.utils.events]: eta: 0:00:00 iter: 299 total_loss: 0.3655 loss_cls: 0.07872 loss_box_reg: 0.1754 loss_mask: 0.07811 loss_rpn_cls: 0.007917 loss_rpn_loc: 0.009371 time: 0.4671 last_time: 0.4684 data_time: 0.0127 last_data_time: 0.0127 lr: 0.00024917 max_mem: 2935M [02/19 12:13:20 d2.engine.hooks]: Overall training speed: 298 iterations in 0:02:19 (0.4672 s / it) [02/19 12:13:20 d2.engine.hooks]: Total training time: 0:02:20 (0:00:01 on hooks)
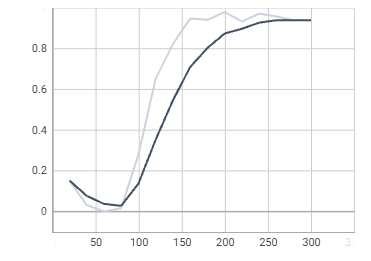
# Look at training curves in tensorboard:
%load_ext tensorboard
%tensorboard –logdir output

fastrcnn / fgcls_accuracy
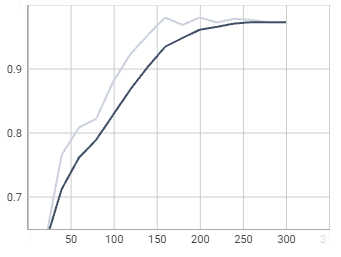
fastrcnn / cls_accuracy
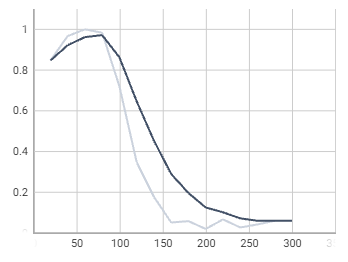
fastrcnn / false_negatives
loss_cls
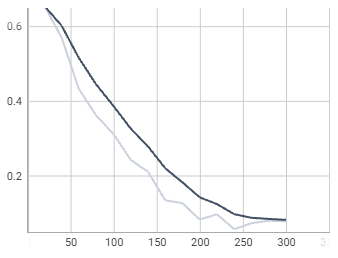
loss_boxreg
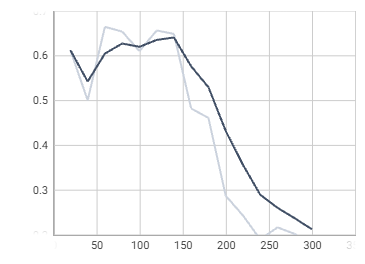
loss_mask

loss_rpn_cls

mask_rcnn_accuracy

mask_rcnn_false_positives
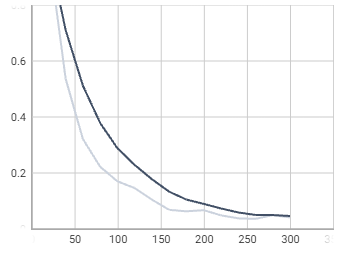
time
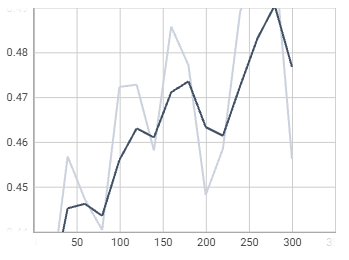
total_loss
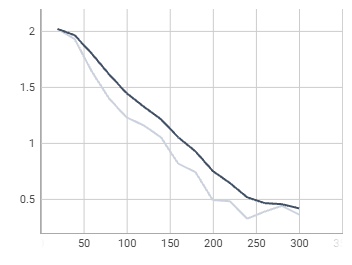
Inference & evaluation using the trained model
Now, let’s run inference with the trained model on the balloon validation dataset. First, let’s create a predictor using the model we just trained:
# Inference should use the config with parameters that are used in training
# cfg now already contains everything we’ve set previously. We changed it a little bit for inference:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, “model_final.pth”) # path to the model we just trained
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set a custom testing threshold
predictor = DefaultPredictor(cfg)
Then, we randomly select several samples to visualize the prediction results.
from detectron2.utils.visualizer import ColorMode
dataset_dicts = get_balloon_dicts(“balloon/val”)
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d[“file_name”])
outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
v = Visualizer(im[:, :, ::-1],
metadata=balloon_metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs[“instances”].to(“cpu”))
cv2_imshow(out.get_image()[:, :, ::-1])

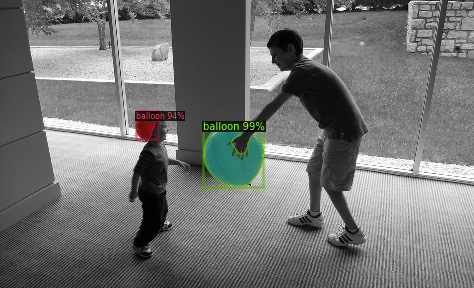

We can also evaluate its performance using AP metric implemented in COCO API. This gives an AP of ~70. Not bad!
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
evaluator = COCOEvaluator(“balloon_val”, output_dir=”./output”)
val_loader = build_detection_test_loader(cfg, “balloon_val”)
print(inference_on_dataset(predictor.model, val_loader, evaluator))
# another equivalent way to evaluate the model is to use `trainer.test`
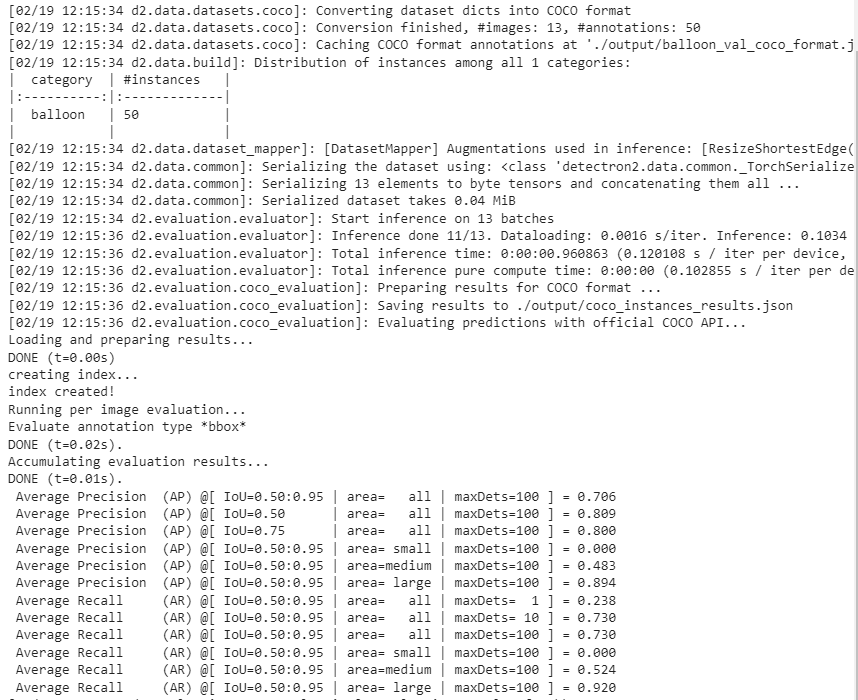
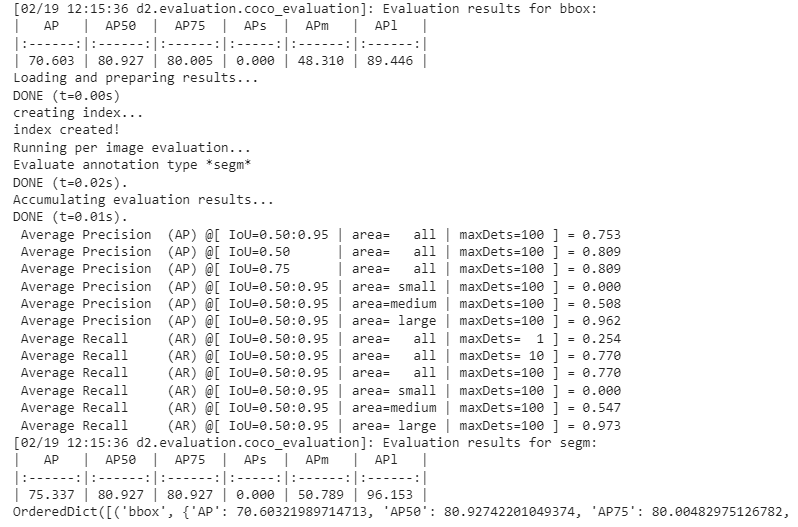
OrderedDict([(‘bbox’, {‘AP’: 70.60321989714713, ‘AP50’: 80.92742201049374, ‘AP75’: 80.00482975126782, ‘APs’: 0.0, ‘APm’: 48.31040246881831, ‘APl’: 89.44611512812692}), (‘segm’, {‘AP’: 75.33730064133776, ‘AP50’: 80.92742201049374, ‘AP75’: 80.92742201049374, ‘APs’: 0.0, ‘APm’: 50.789378937893794, ‘APl’: 96.15284780357734})])
Other types of built-in models
We showcase simple demos of other types of models below
# Inference with a keypoint detection model
cfg = get_cfg() # get a fresh new config
cfg.merge_from_file(model_zoo.get_config_file(“COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml”))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set threshold for this model
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(“COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml”)
predictor = DefaultPredictor(cfg)
outputs = predictor(im)
v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs[“instances”].to(“cpu”))
cv2_imshow(out.get_image()[:, :, ::-1])

# Inference with a panoptic segmentation model
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(“COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml”))
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(“COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml”)
predictor = DefaultPredictor(cfg)
panoptic_seg, segments_info = predictor(im)[“panoptic_seg”]
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_panoptic_seg_predictions(panoptic_seg.to(“cpu”), segments_info)
cv2_imshow(out.get_image()[:, :, ::-1])

Summary
- Today we discussed inferences and QC evaluation of Detectron2 using a set of built-in and trained models.
- Test results and showcase demos confirm that Detectron2 is a very powerful CV platform that provides developers and enterprises a comprehensive framework for building, deploying, and managing real-scale object detection applications on various devices.
Business Applications
- Retail: AI-Powered Video Analytics, Contactless Checkout, Inventory Management, Foot Traffic Analysis, Customer Experience, etc.
- Industrial use cases such as PPE Detection, Product Assembly, Anomaly and Defect Detection, and Productivity Improvement.
- Transportation and Smart City: Autonomous Driving, Traffic Monitoring & Road Maintenance, People Counting, Parking Occupancy, In-Cabin Monitoring, Alternative transportation, ADA Compliance, etc.
- Security & Safety.
Explore More
Multi-Label Keras CNN Image Classification of MNIST Fashion Clothing
BTC-USD Price Prediction with LSTM Keras
AI-Driven Stock Prediction using Keras LSTM Models


Make a one-time donation
Make a monthly donation
Make a yearly donation
Choose an amount
Or enter a custom amount
Your contribution is appreciated.
Your contribution is appreciated.
Your contribution is appreciated.

{kind=link}
Leave a comment