

Introduction
Workflow

Input Data
- Sex – Gender of patient Male = 1, Female =0
- Age – Age of patient
- Diabetes – 0 = No, 1 = Yes
- Anaemia – 0 = No, 1 = Yes
- High_blood_pressure – 0 = No, 1 = Yes
- Smoking – 0 = No, 1 = Yes
- DEATH_EVENT – 0 = No, 1 = Yes

RangeIndex: 299 entries, 0 to 298 Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 299 non-null float64 1 anaemia 299 non-null int64 2 creatinine_phosphokinase 299 non-null int64 3 diabetes 299 non-null int64 4 ejection_fraction 299 non-null int64 5 high_blood_pressure 299 non-null int64 6 platelets 299 non-null float64 7 serum_creatinine 299 non-null float64 8 serum_sodium 299 non-null int64 9 sex 299 non-null int64 10 smoking 299 non-null int64 11 time 299 non-null int64 12 DEATH_EVENT 299 non-null int64





age is 77 but for chol it is 564. Thus, feature scaling must be performed on the dataset [6].Exploratory Data Analysis
Is Age and Sex an indicator for Death Event?
- Age wise 40 to 80 the spread is High
- less than 40 age and higher than 80 age people are very low



























Age Report
- Survival spread is high in age’s flow of 40 to 70
- The Survival is high for both male between 50 to 60 and female’s age between 60 to 70 respectively
Smoking
- The Survival is high for not smoking person 55 to 65, while for smoking person it is between 50 to 60
- Death event for smoking person is high than not smoking person
- From above pie charts we can conclude that in our dataset diabetes from 203 of Non Smoking person 137 are survived and 66 are not survived and
- From 96 Smoking person 66 are survived, while 30 are not survived.
- From above pie charts we can conclude that in our dataset diabetes from 194 of Non High BP person 137 are survived and 57 are not survived and
- From 105 High BP person 66 are survived, while 39 are not survived.
Feature Engineering

It’s easy to see that there is no single feature that has a very high correlation with our target value. Also, some of the features have a negative correlation with the target value and some have positive.
Accuracy Analysis
K Neighbors Classifier
This classifier looks for the classes of K nearest neighbors of a given data point and based on the majority class, it assigns a class to this data point. However, the number of neighbors can be varied. I varied them from 1 to 20 neighbors and calculated the test score in each case [6]:
# K Neighbors Classifier
kn_clf = KNeighborsClassifier(n_neighbors=6)
Support Vector Classifier
kernels based on which the hyperplane is decided. I tried four kernels namely, linear, poly, rbf, and sigmoid. The linear kernel performed the best for this dataset [6]. Decision Tree Classifier
This classifier creates a decision tree based on which, it assigns the class values to each data point. Here, we can vary the maximum number of features to be considered while creating the model. I range features from 1 to 30 (the total features in the dataset after dummy columns were added).
Random Forest Classifier

As one can see below, classification accuracy of up to 93% was achieved in the prediction of HF risk using the Gradient Boosting or XGBRF Classifier with this dataset.
Accuracy of Logistic Regression is : 90.00%
Accuracy of SVC is : 90.00%
Accuracy of K Neighbors Classifier is : 91.67%
Accuracy of Decision Tree Classifier is : 90.00%Accuracy of Random Forest Classifier is : 90.00%Accuracy of Gradient Boosting is : 93.33%Accuracy of XGBRFClassifier is : 93.33%Accuracy of LGBMClassifier is : 86.67%Accuracy of CatBoostClassifier is : 91.67%Confusion Matrix
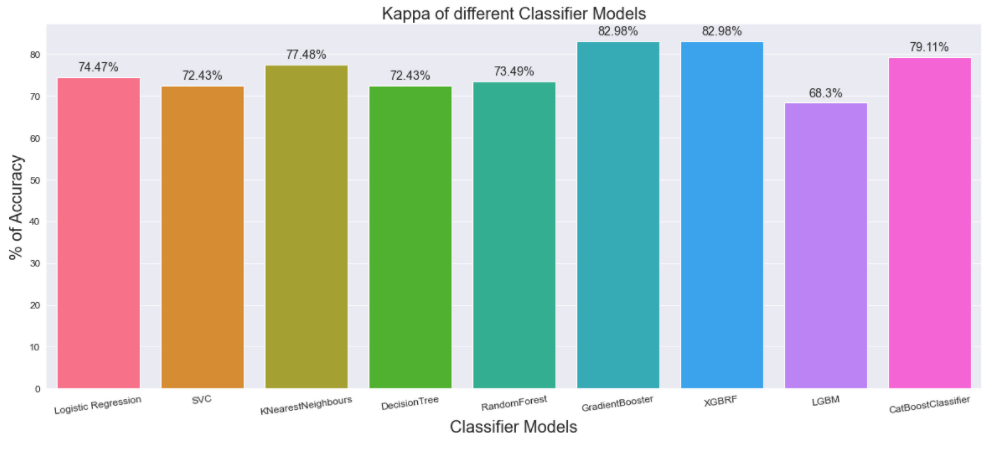
Confusion Matrix is the most effective tool to analyse HF prediction in this field of study.Sensitivity/recall indicates the proportions of cardiac patients diagnosed by the model as with HF. Precision provides information about the proportion of those classified by the model as with HF, had HF. F1 Score is defined as the harmonic mean of sensitivity/recall and precision assigning a single number. Specificity indicates the proportions of patients not having HF been forecasted by the model to the category of non-cardiac disease.log_reg_predPrecision: 0.866667 Recall: 0.764706 F1 score: 0.812500 Cohens kappa: 0.744681sv_clf_predPrecision: 1.000000 Recall: 0.647059 F1 score: 0.785714 Cohens kappa: 0.724349kn_predPrecision: 1.000000 Recall: 0.705882 F1 score: 0.827586 Cohens kappa: 0.774775dt_predPrecision: 1.000000 Recall: 0.647059 F1 score: 0.785714 Cohens kappa: 0.724349r_predPrecision: 0.923077 Recall: 0.705882 F1 score: 0.800000 Cohens kappa: 0.734904gradientboost_predPrecision: 0.933333 Recall: 0.823529 F1 score: 0.875000 Cohens kappa: 0.829787xgb_predPrecision: 0.933333 Recall: 0.823529 F1 score: 0.875000 Cohens kappa: 0.829787lgb_predPrecision: 0.736842 Recall: 0.823529 F1 score: 0.777778 Cohens kappa: 0.682959cat_predPrecision: 0.875000 Recall: 0.823529 F1 score: 0.848485 Cohens kappa: 0.791086Cohen’s kappa is a robust statistic useful for either interrater or intrarater reliability testing. Cohen suggested the Kappa result be interpreted as follows: values ≤ 0 as indicating no agreement and 0.01–0.20 as none to slight, 0.21–0.40 as fair, 0.41– 0.60 as moderate, 0.61–0.80 as substantial, and 0.81–1.00 as almost perfect agreement. In healthcare research, many texts recommend 80% agreement as the minimum acceptable interrater agreement. In our case, the only gradientboost and xgbrf satisfy this condition.Classification Summary
The results of the proposed work depict that Gradient Booster or XGBRF is better than the other supervised classifiers in terms of the discussed performance metrics – accuracy, precision, recall, and F1 score. The model gives the results with the highest accuracy of 93.33%. The classifier is also less risky since the number of false negatives is low as compared to other models as per the confusion matrix of all the models.E-Learning
Check out these links below:
Cloud APIs
GCP AutoML enables data specialists with limited ML expertise to train high-quality models specific to their business needs.Microsoft Azure Machine Learning Studio (classic):the web portal for data scientist developers in Azure Machine Learning. The studio combines no-code and code-first experiences for an inclusive data science platform.
References















Leave a comment